EDRM-Aligned Workflow
How Discovarc Works
Four phases that map to the discovery lifecycle — from raw document collection to defensible production set. Each phase is a distinct workflow step, not a black box.
Where Discovarc fits in the EDRM
The Electronic Discovery Reference Model defines six phases. Discovarc operates from Processing through Production — the phases where volume and consistency matter most.
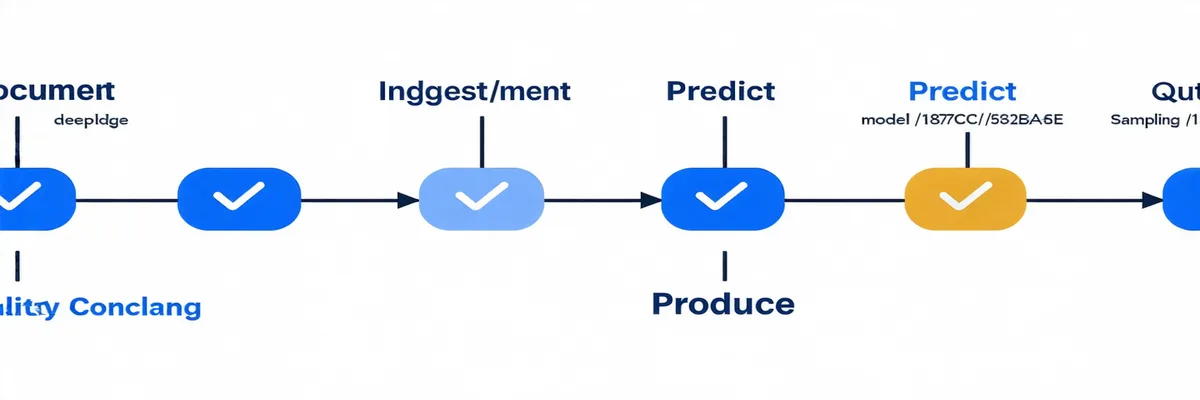
Ingest
Document collections arrive in diverse formats across multiple custodians. Discovarc processes each document set into a normalized review corpus before any predictive model sees the data.
What happens in Ingest
- Email threads de-duplicated and attached across PST, EML, and MBOX collections
- Near-duplicate document clustering reduces redundant reviewer effort
- Custodian metadata preserved and mapped to document lineage
- Native document formats converted to reviewable format: PDF, DOCX, TIFF, MSG, XLSX
- Foreign-language documents flagged for separate handling
Predict
The predictive model learns from attorney reviewer decisions. A seed set — a stratified initial training batch selected by counsel — provides the signal the model needs to begin ranking the full document population.
Continuous Active Learning (TAR 2.0)
Unlike simple passive learning (TAR 1.0), Discovarc uses continuous active learning: the model updates with each reviewer decision, prioritizing uncertain documents for the next review round. This means the model improves throughout the review — not just at a fixed training checkpoint.
What gets predicted
- Responsive / Non-Responsive classification on each document
- Privilege indicator signals (attorney names, legal hold context, outside counsel)
- Confidence score (0–100) informing QC tier assignment
Quality Control
QC is a distinct workflow step — not a subset of the review pass. Discovarc assigns every document to a confidence tier; QC sampling is stratified across those tiers to ensure statistical defensibility.
QC workflow elements
- Stratified random sampling: high-confidence, mid-confidence, and near-cutoff tiers sampled at distinct rates
- Elusion testing: random sample from predicted non-responsive set validates recall rate
- Exception workflow: documents that fail QC thresholds routed to secondary review, not discarded
- Confidence threshold calibration: allows supervising attorney to adjust recall vs. precision trade-off
Produce
Production output is formatted for the target review platform. Discovarc generates load files in industry-standard formats with Bates numbering applied to the production set.
Production outputs
- Load file export: Relativity .DAT/.OPT, IPRO .LFP, Summation .DII
- Privilege log generation: date, author, recipient, subject, privilege basis, document type
- Bates number assignment with prefix/suffix customization
- Production set packaging with cover sheet and certificate of production
- Audit trail export for protocol disclosure under FRCP Rule 26
Walk through your matter type with us.
We'll map the four phases to your specific collection format, custodian structure, and production target.
Request a Walkthrough